第二章 AI复兴:深度学习+大数据=人工智能(第14/20页)
其实,要教计算机认字,差不多也是同样的道理。计算机也要先把每一个字的图案反复看很多很多遍,然后,在计算机的大脑(处理器加上存储器)里,总结出一个规律来,以后计算机再看到类似的图案,只要符合之前总结的规律,计算机就能知道这图案到底是什么字。
用专业的术语来说,计算机用来学习的、反复看的图片叫“训练数据集”;“训练数据集”中,一类数据区别于另一类数据的不同方面的属性或特质,叫作“特征”;计算机在“大脑”中总结规律的过程,叫“建模”;计算机在“大脑”中总结出的规律,就是我们常说的“模型”;而计算机通过反复看图,总结出规律,然后学会认字的过程,就叫“机器学 习”。
到底计算机是怎么学习的?计算机总结出的规律又是什么样的呢?这取决于我们使用什么样的机器学习算法。
有一种算法非常简单,模仿的是小朋友学识字的思路。家长和老师们可能都有这样的经验:小朋友开始学识字,比如先教小朋友分辨“一”“二”“三”时,我们会告诉小朋友说,一笔写成的字是“一”,两笔写成的字是“二”,三笔写成的字是“三”。这个规律好记又好用。但是,开始学新字时,这个规律就未必奏效了。比如,“口”也是三笔,可它却不是“三”。我们通常会告诉小朋友,围成个方框儿的是“口”,排成横排的是“三”。这规律又丰富了一层,但仍然禁不住识字数量的增长。很快,小朋友就发现,“田”也是个方框儿,可它不是“口”。我们这时会告诉小朋友,方框里有个“十”的是“田”。再往后,我们多半就要告诉小朋友,“田”上面出头是“由”,下面出头是“甲”,上下都出头是“申”。很多小朋友就是在这样一步一步丰富起来的特征规律的指引下,慢慢学会自己总结规律,自己记住新的汉字,并进而学会几千个汉字 的。
有一种名叫决策树的机器学习方法,就和上面根据特征规律来识字的过程非常相似。当计算机只需要认识“一”“二”“三”这三个字时,计算机只要数一下要识别的汉字的笔画数量,就可以分辨出来了。当我们为待识别汉字集(训练数据集)增加“口”和“田”时,计算机之前的判定方法失败,就必须引入其他判定条件。由此一步步推进,计算机就能认识越来越多的字。

图24 计算机分辨“一”“二”“三”“口”“田”的决策树
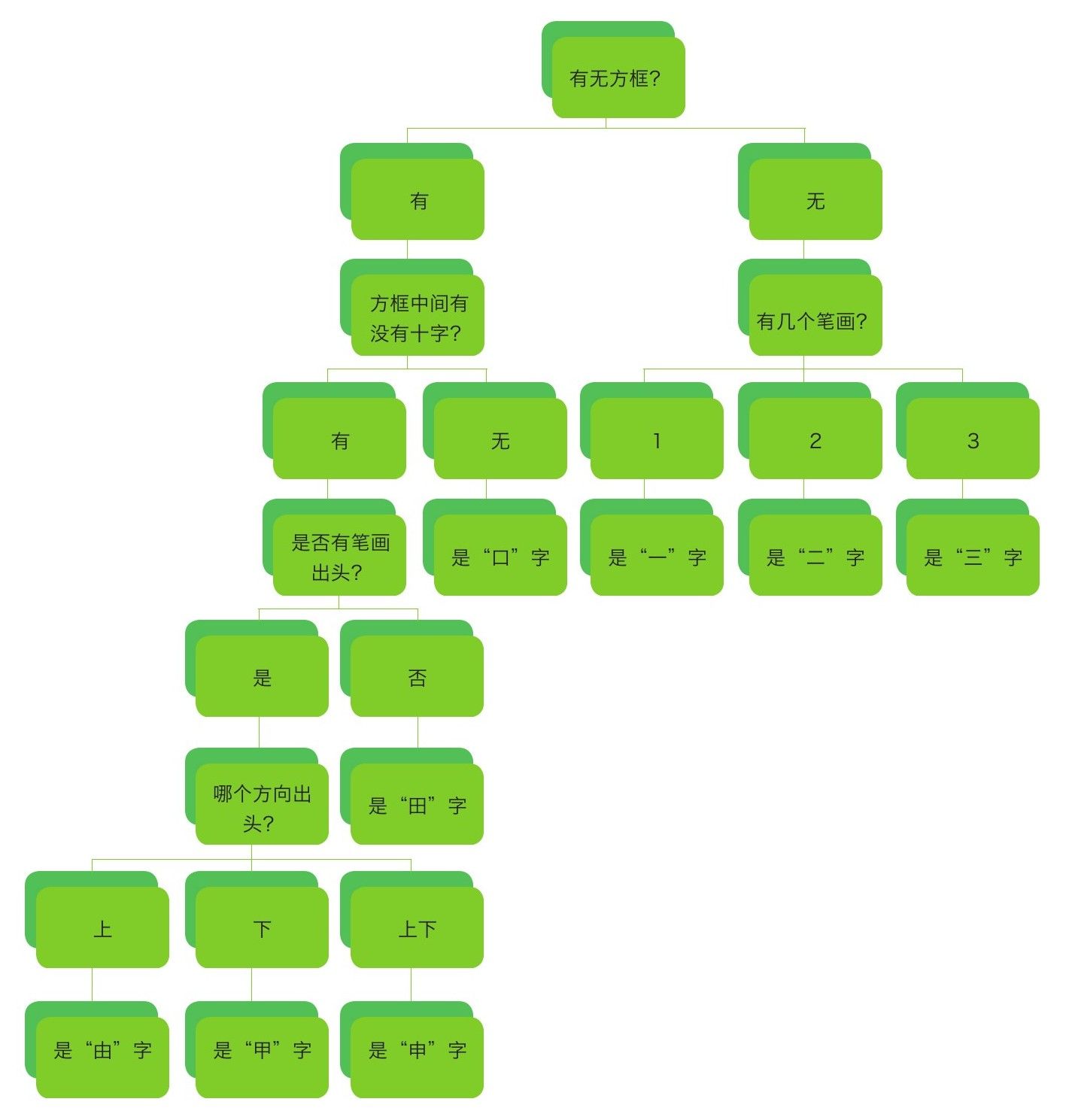
图25 计算机学习了“由”“甲”“申”三个新汉字之后的决策树
图25显示了计算机学习“由”“甲”“申”这三个新汉字前后,计算机内部的决策树的不同。这说明,当我们给计算机“看”了三个新汉字及其特征后,计算机就像小朋友那样,总结并记住了新的规律,“认识”了更多的汉字。这个过程,就是一种最基本的机器学习了。
当然,这种基于决策树的学习方法太简单了,很难扩展,也很难适应现实世界的不同情况。于是,科学家和工程师们陆续发明出了许许多多不同的机器学习方法。
例如,我们可以把汉字“由”“甲”“申”的特征,包括有没有出头、笔画间的位置关系等,映射到某个特定空间里的一个点(我知道,这里又出现数学术语了。不过这不重要,是否理解“映射”的真实含义,完全不影响后续阅读)。也就是说,训练数据集中,这三个字的大量不同写法,在计算机看来就变成了空间中的一大堆点。只要我们对每个字的特征提取得足够好,空间中的一大堆点就会大致分布在三个不同的范围里。
这时,让计算机观察这些点的规律,看能不能用一种简明的分割方法(比如在空间中画直线),把空间分割成几个相互独立的区域,尽量使得训练数据集中每个字对应的点都位于同一个区域内。如果这种分割是可行的,就说明计算机“学”到了这些字在空间中的分布规律,为这些字建立了模 型。
接下来,看见一个新的汉字图像时,计算机就简单把图像换算成空间里的一个点,然后判断这个点落在了哪个字的区域里,这下,不就能知道这个图像是什么字了吗?